读《Malware Data Science》
今年一直在强迫自己有空多看点书,会慢慢分享一些读后感。
《Malware Data Science》这本书读之前我的期望比较高,虽然我没打算深入做这个方向,但是现在太多关于病毒分析的书了,写来写去都是那些东西,有这么一本从数据科学的角度讲病毒分析的书感觉很难得。但是大致读完之后,还是有点失望。满分100分只能打个60分,个人觉得属于读不读都可以的那种。
这本书一共有12章,第1章是介绍,第2章是静态分析,第3章是动态分析,可以直接跳过。下面重点说第4章到第12章。
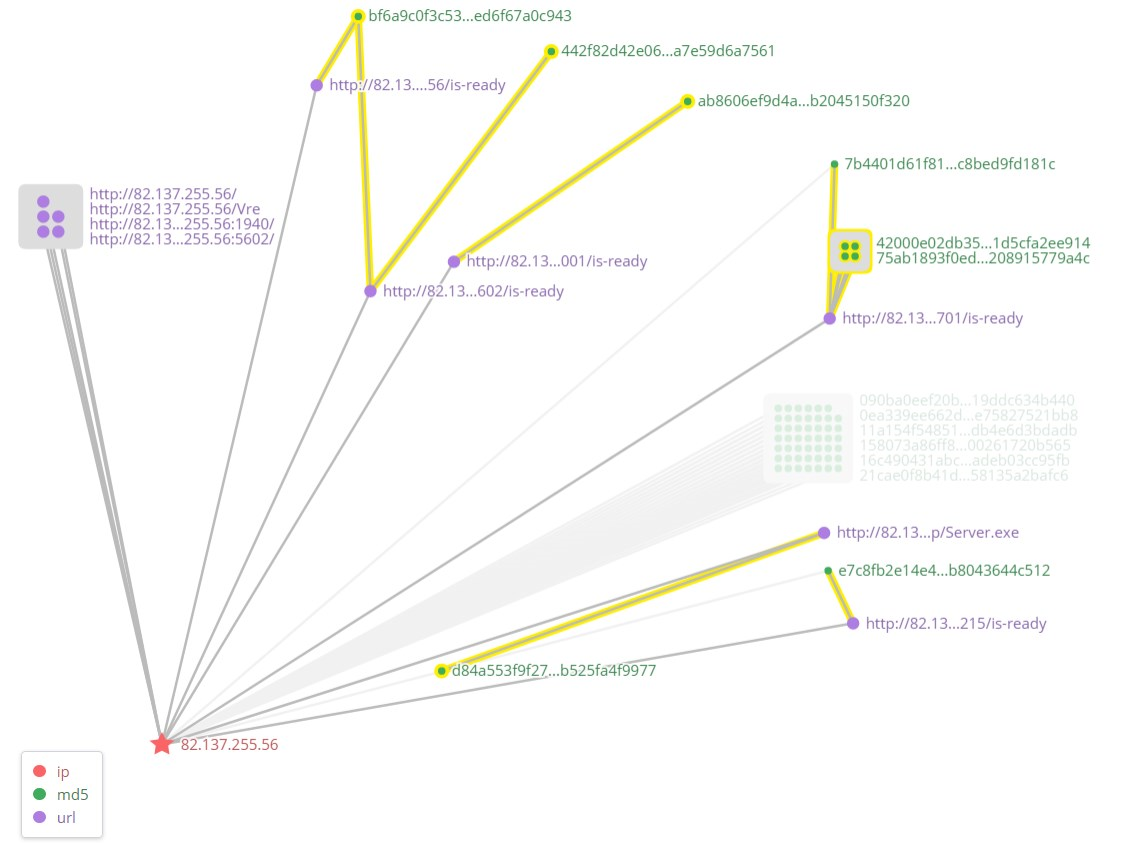
第4章:教你怎么画图来识别攻击活动。书上举的两个例子一是把相同CC的样本连在一起,二是把含有相同图片的样本连在一起,分别用的APT1和木马样本。大概效果像下面这样。
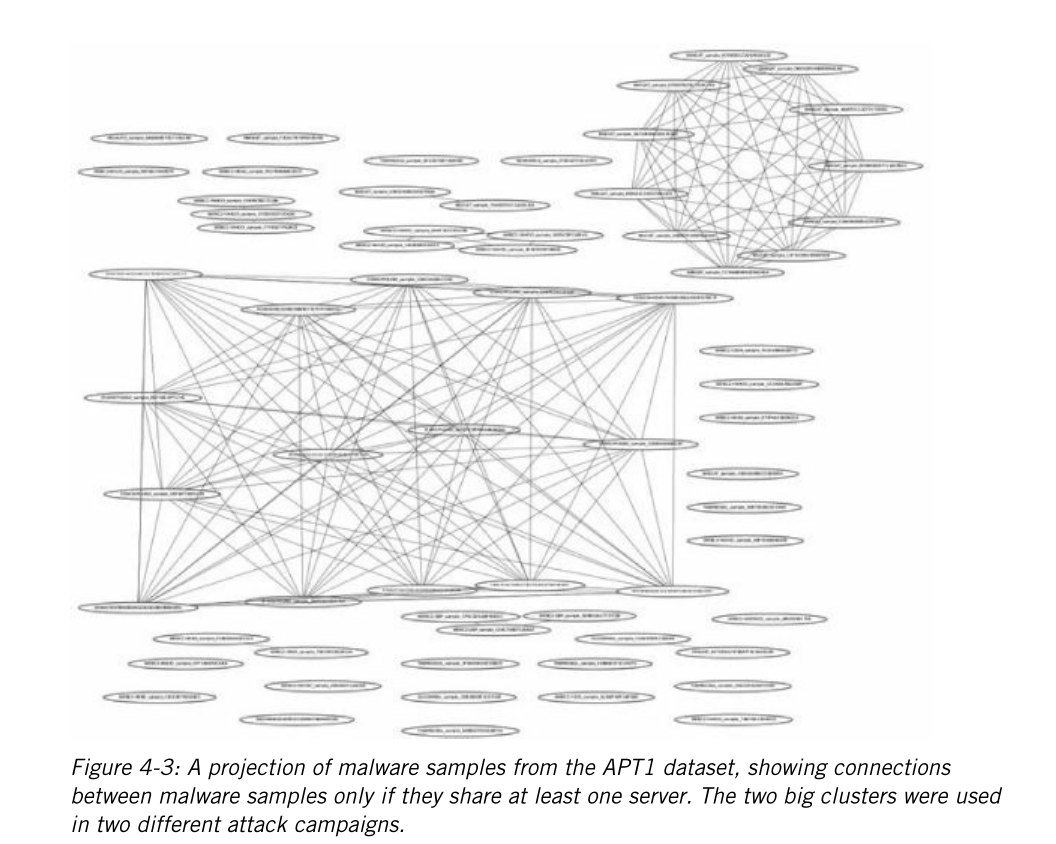
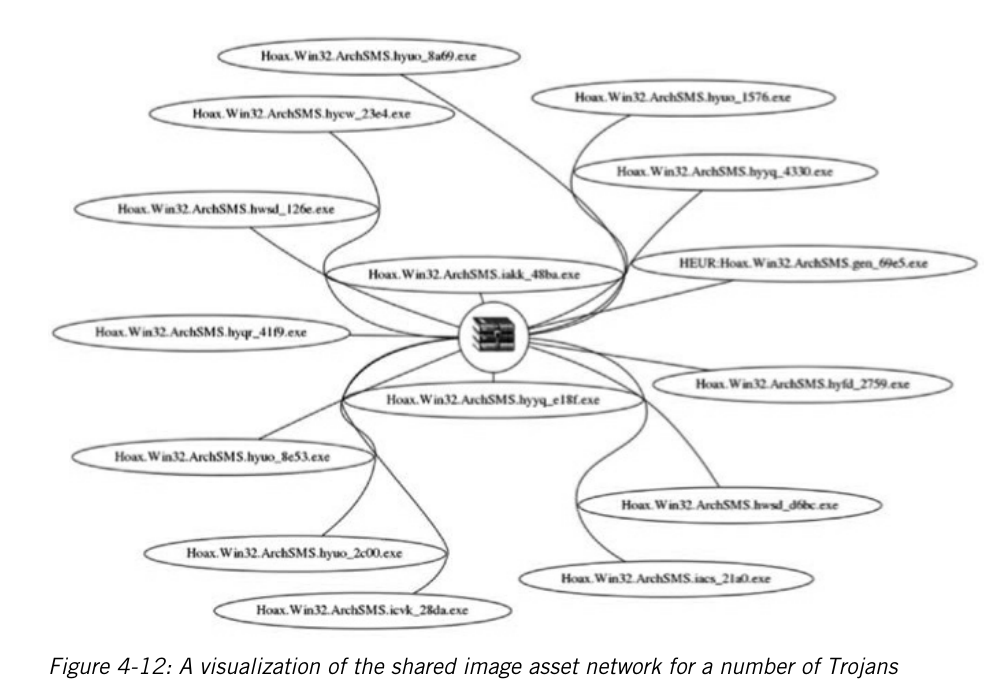
大家都懂的,想看的话就别指望国内出翻译版了。
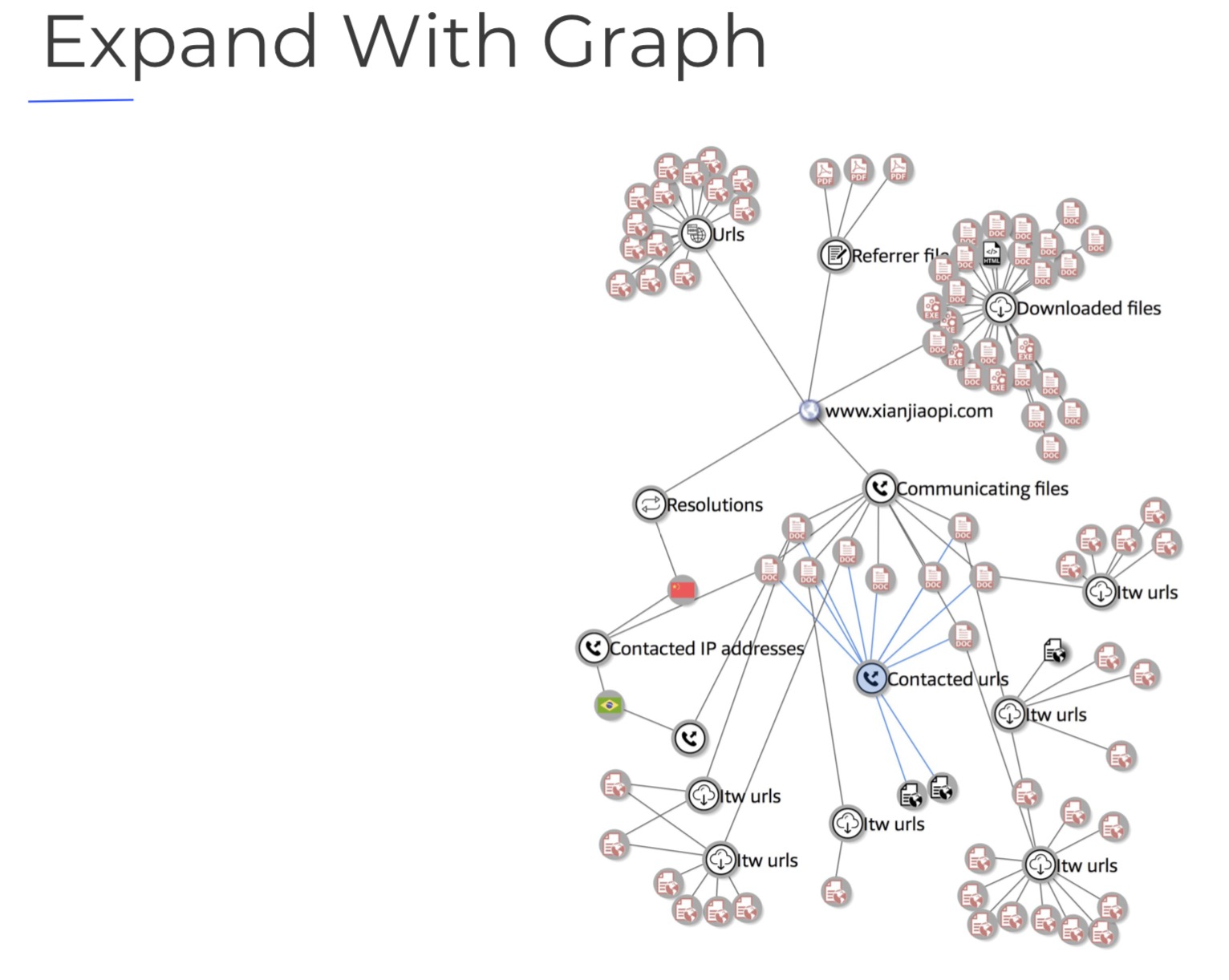
这种系统首先就是大名鼎鼎的virustotal的VTgraph了,virustotal官方还出了个virustotal的教程:https://storage.googleapis.com/vt-gtm-wp-media/virustotal-for-investigators.pdf
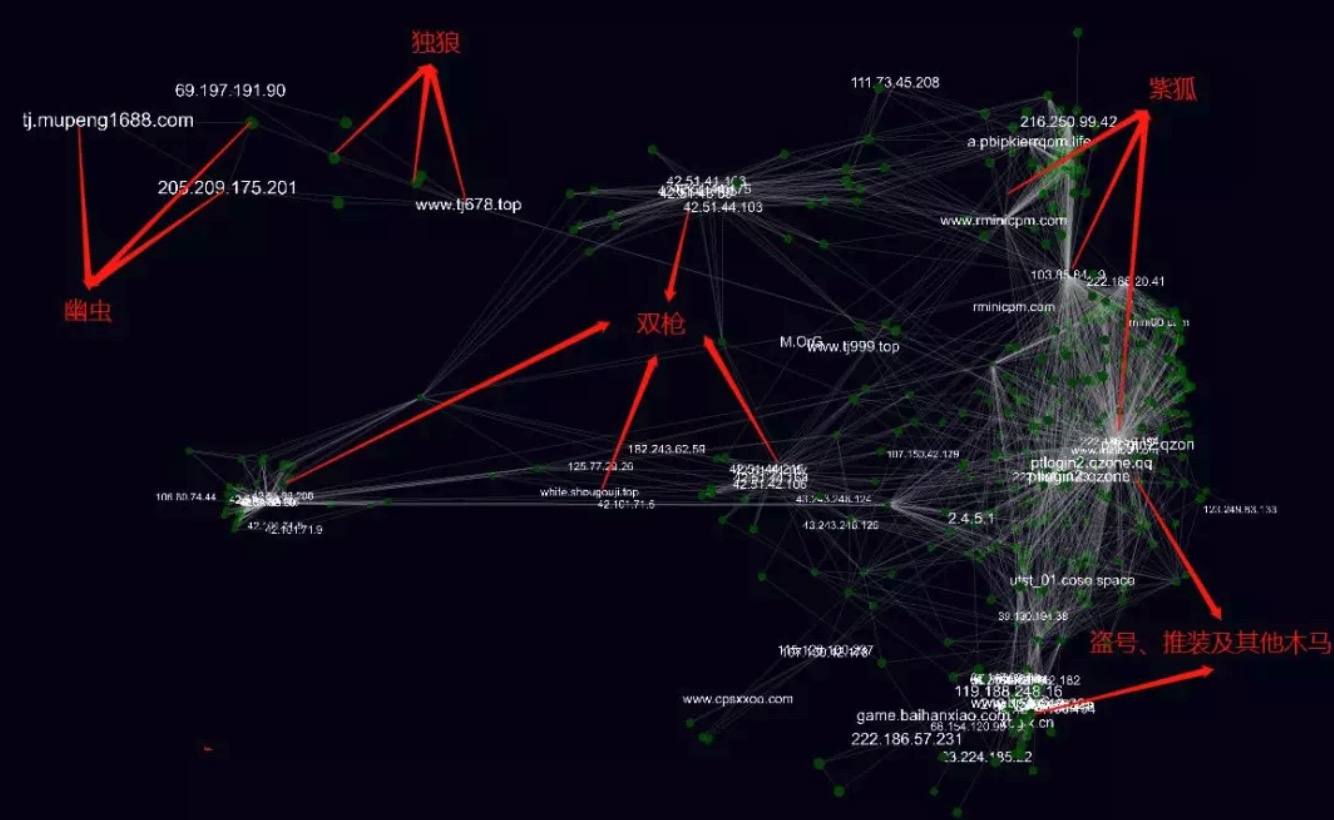
国内这样的系统还有腾讯的安图,前几天它们一篇文章中判断今年几个影响恶劣的病毒团伙背后是同一个犯罪组织:https://mp.weixin.qq.com/s/tmNYp1WHtUxYRE3aRQNUeA
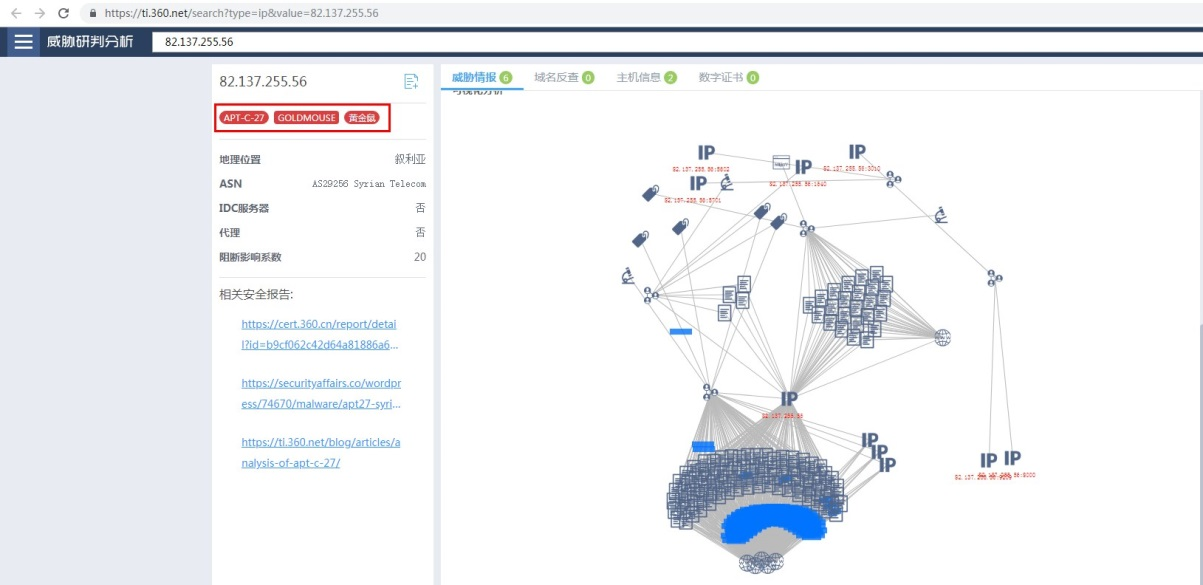
当然还有360网络研究院大数据关联平台和360威胁情报中心(现更名为奇安信威胁情报中心)威胁分析平台:https://ti.360.net/blog/articles/apt-c-27-(goldmouse):-suspected-target-attack-against-the-middle-east-with-winrar-exploit/
还有微步在线等平台,就不一一列举了。
第5章:共享代码识别,这个其实是很有用的一个功能。比如为什么说VPNFilter与BlackEnergy有关,因为它们都用了相同的方式去修改RC4算法进行加密,如果在分析的时候有这样一个共享代码识别的系统,样本扔进去就跑出来识别出共享了BlackEnergy的代码,能省很多精力和时间。这样的系统目前intezer有一个。
这个是免费的,花钱可以有更多高级功能。
书上说了有这么几个方法识别二进制文件共享代码:汇编指令,字符串,IAT表,动态API调用。我估计intezer大概主要也就是汇编指令和字符串。最后基于字符串做了一个简单的命令行查询系统。
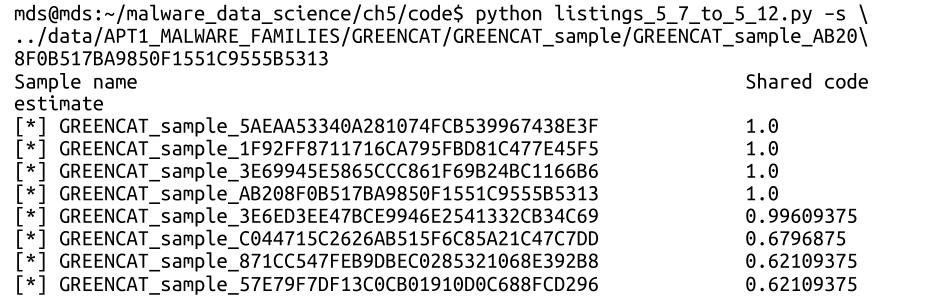
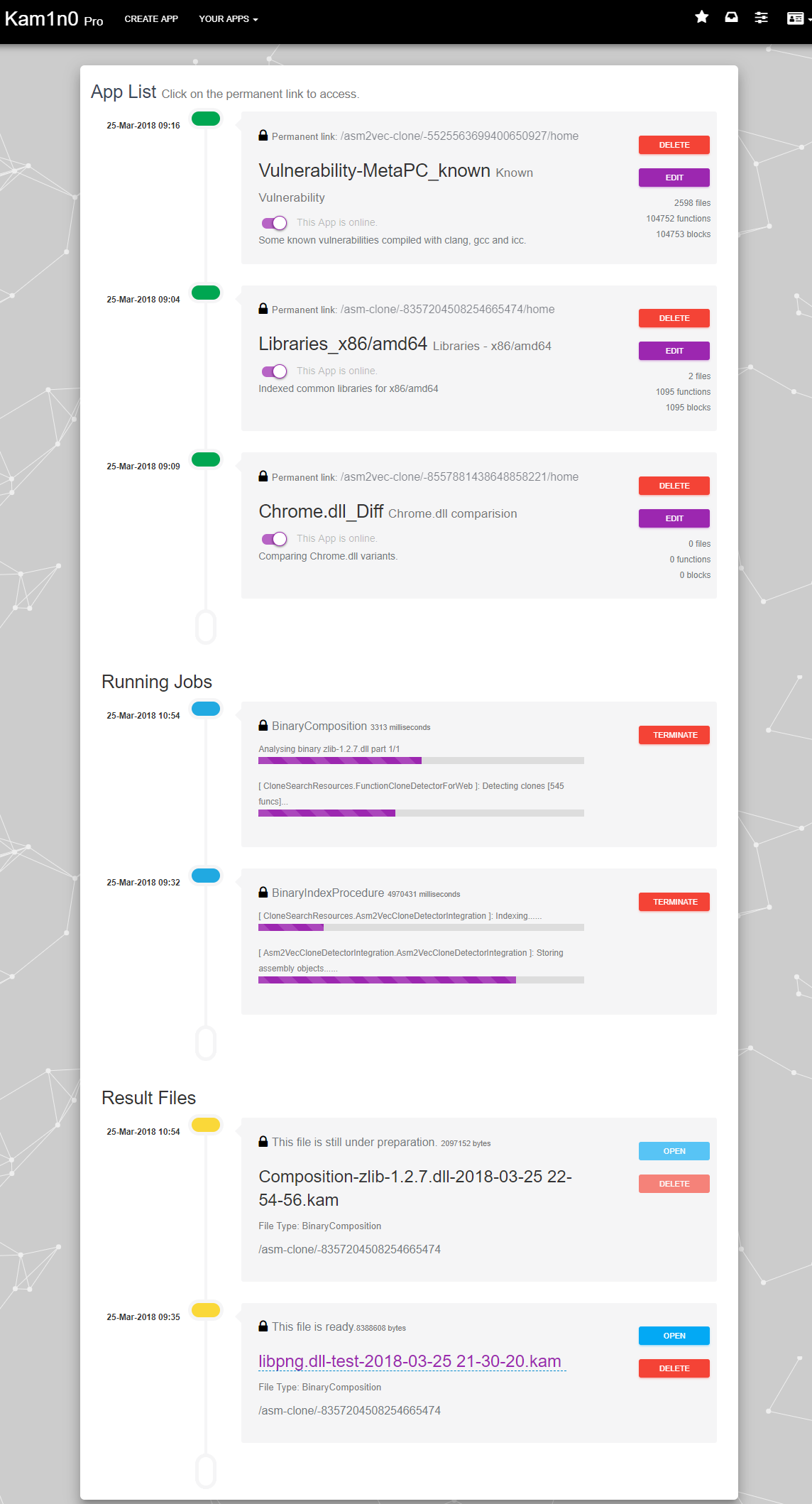
还有一个开源的IDA插件Kam1n0,是2015年IDA插件大赛的第二名:https://github.com/McGill-DMaS/Kam1n0-Community
第6章:扯了一些机器学习的概念。介绍了机器学习的步骤,特征空间和决策边界概念,模型的过拟合和欠拟合问题,和几个机器学习的算法:逻辑回归,KNN,决策树和随机森林。
第7章:扯了一些机器学习的评价指标。TP、TN、FP、FN,ROC,Precision,TPR,FPR等等。懂机器学习的话,这两章可以直接跳过。
第8章:先用是否被加密和压缩这两个指标作为特征,决策树作为算法写了一个判定恶意文件和正常文件的很简单的示例代码。然后实现了一个更接近实际用的,提取字符串作为特征,随机森林作为算法。
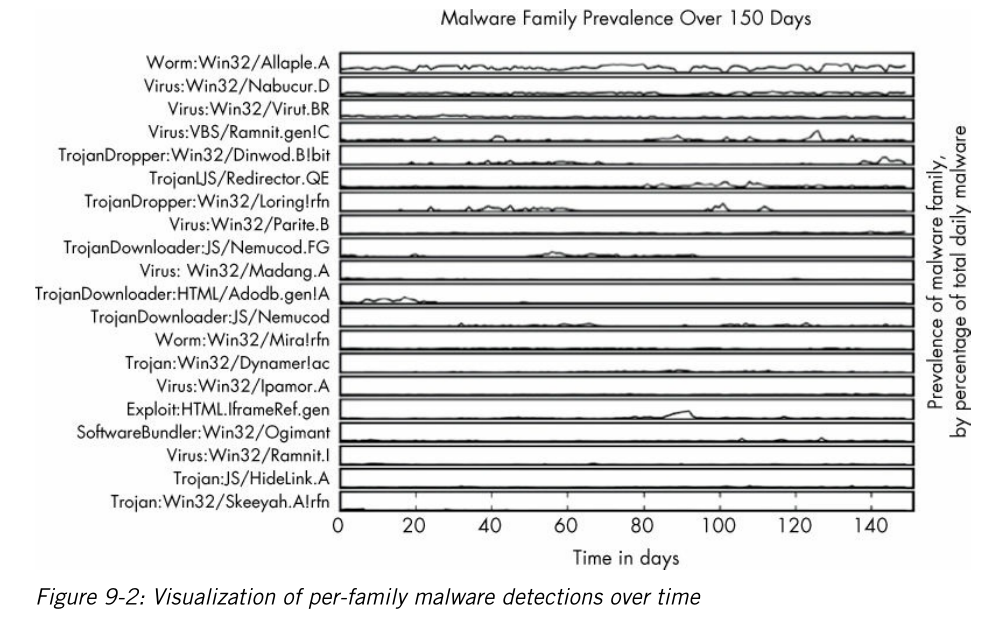
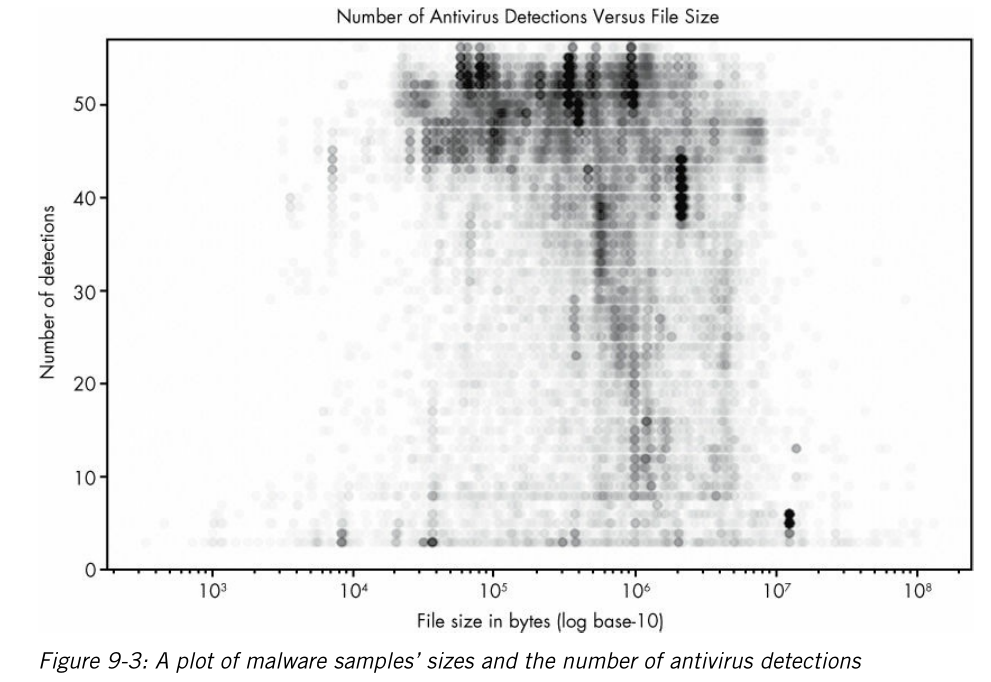
第9章:可视化,教你怎么画一些比较高大上的图,随便截了几张。
第10章:扯了一些深度学习的概念。神经网络原理是什么,怎么训练神经网络,最后介绍了几种神经网络:前向神经网络,卷积神经网络,自编码神经网络,生成对抗网络,循环神经网络和残差网络。懂的话也可以直接跳过。
第11章:用神经网络检测恶意HTML页面。
第12章:怎么成为一个数据科学家,随便扯扯。
数据科学用于病毒分析当然能做很多有趣的事情。但是打60分的原因是觉得翻翻还是可以,例子都太简单了,机器学习/深度学习这种玄学类的东西,举那么简单的例子基本等于没有举,真正用于实践会遇到很多问题。
其实我是买了书的,但是纸质看起来不太方便,又找了好久才找到pdf,想看看这本书又找不到pdf的话:aG91amluZ3lpMTU5。

读《Malware Data Science》
https://houjingyi233.com/2019/04/01/读《Malware Data Science》/

